c 语言常见未定义行为
本文所用的 language standard: c11
最近经常遇到有人来问一些稀奇古怪的代码为什么运行结果不符合预期, 而这些神乎其技的代码十有八九都是未定义行为, 特此记录几个经常遇到的未定义行为以供查阅.
什么是未定义行为
未定义行为(undefined behavior)(简称 UB)指编译器允许编译, 但是语言标准中没有定义的行为. 这种现象的出现并不是语言标准不完善, 而是因为这种行为在编译时无法检查其错误或者受限于具体的 cpu 指令以及操作系统优化等使其会有在编译时不可预知的运行结果.
最简单的就是数组越界, 这种错误在 c 语言编译时无法检查, 而 c 标准也没有定义越界后会访问到什么.
未定义行为在不同编译器上或者不同操作系统或者不同架构 cpu 上会产生不同的结果, 所以在任何代码中都应当避免未定义行为.
常见未定义行为
数组越界
平时俗称的数组越界实际上是指 数组下标越界(array index out of bounds). 数组越界是最常见的一种未定义行为(一般情况下也是一种错误). 例如以下代码
void func() {
int array[5] = {0};
printf("%d", array[5]);
}
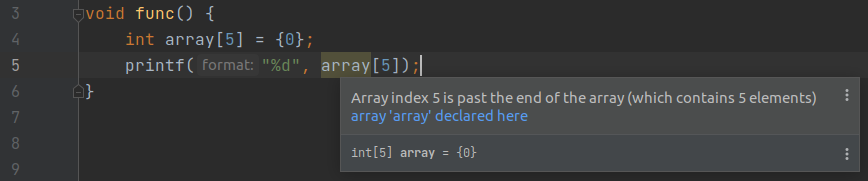
显然数组下标最大为 4, 但是却访问了 5. 在 Jetbrains Clion 中可以看到此处的代码错误提示.
而至于 array[5] 到底会访问到什么取决于操作系统和编译器. 例如 windows 平台的 msvc 编译器的 debug 模式会将所有未初始化内存都用特定值来充填, 在未初始化内存的边缘会用另一个值来充填(详见烫烫烫屯屯屯问题). 但是在 linux 平台的 gcc 中此时只会访问到一个普通的未初始化内存, 因此其值是不可预期的.
如果所访问的内存并没有在代码中申请过, 那么这块内存就有可能在操作系统分配给程序的内存之外, 此时就会产生以下结果(控制台输出)
Signal: SIGSEGV (Segmentation fault)
Process finished with exit code 1
平时俗称的段错误实际上指 存储器区段错误(segmentation fault), 这种错误最早用来表示程序企图访问一个 cpu 无法寻址的内存地址(超过了物理内存的长度), 而现代操作系统为了避免程序可以访问操作系统或者其他程序的内存, 会在程序企图访问一个地址前检查其访问权限(并且现代操作系统会对程序可以访问的内存做内存映射, 程序中取得的地址并不是真实物理地址), 因此现代段错误还包含访问权限冲突(access violation).
一旦程序出现段错误, 程序就会收到 SIGSEGV 信号, "SIG" 是 unix 信号的固定前缀, "SEGV" 是段违例(segmentation violation). 如果程序没有捕获这个信号, 默认动作是异常终止.
#include <stdio.h>
#include <signal.h>
#include <stdlib.h>
void signalHandler(int signalNumber) {
printf("Signal number: %d\n", signalNumber);
exit(0);
}
int main() {
signal(SIGSEGV, signalHandler);
int var = *(int *) 0x0;
printf("%d", var);
return 0;
}
(所有的信号都是 signal.h 里定义的宏)
也可以通过捕获 SIGSEGV 来使程序看起来正常退出(return 0), 虽然这并没有什么用.
值得注意的是, 与其他常见信号比如 SIGINT (ctrl c)不同, 如果程序捕获了 SIGINT 并且没有在 handler 中退出程序, 那么程序在 handler 返回后会从被中断的那一行的下面一行继续运行. 而 SIGSEGV 即使被捕获, handler 结束运行后会再次触发 SIGSEGV 使 handler 又被执行一次. 如果 handler 没有退出程序就会在出现段错误的这一行无限循环执行 handler. 因此并不能通过捕获 SIGSEGV 来强行使程序继续运行下去.
修改字符串字面量
字面量(literal)是写在源代码中的表示固定值的符号(token). 平时俗称的硬编码(hard coding)大多数时候就是在说字面量(有时指常量). 举个例子
const int var1 = 1;
int var2 = 1;
var2 = 2;
其中 var1 是常量, var2 是变量, 1 是字面量.
基本类型的字面量在机器码里也是字面量. 修改字符串字面量说的是这种情况
char *string = "Hello";
string[0] = 'h';
上述代码会在第二行产生段错误.
在了解只读数据之前, 先尝试以下代码
#include <stdio.h>
int main() {
char *string1 = "Hello";
char *string2 = "Hello";
printf("%ld %ld", (long) string1, (long) string2);
return 0;
}
以 linux 平台为例, 这段代码将打印出两个相同的内存地址, 由此可以证明 "Hello" 这个字面量是全 ELF 共享的, 无论有多少个使用了 "Hello" 的地方, 它们都会指向同一个地址.
*nix 平台所用的二进制文件(包括共享库与可执行文件)被称为 ELF, 其典型结构如下
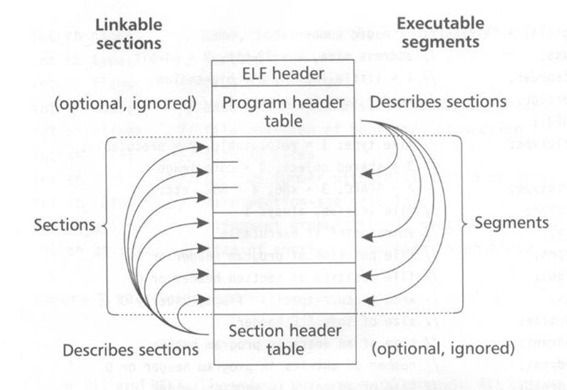
一个 ELF 包含以下几个部分
- ELF 头(ELF header)
- 程序头(program headers)
- 节头(section headers)
- sections
ELF header 存储在 ELF 文件的起始位置, 包含一个用于表示文件格式的魔数(magic number)以及一系列程序基本信息, 使用 readelf 可以读取出其中的内容
$ readelf -h c_sample
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Shared object file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x4f0
Start of program headers: 64 (bytes into file)
Start of section headers: 8648 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 9
Size of section headers: 64 (bytes)
Number of section headers: 33
Section header string table index: 32
一个程序的各个部分会被拆分为很多个 sections 存储在 ELF 中, sections 的数量根据操作系统和程序的不同会有不固定的个数, 每个 section 包含的数据多少也是不固定的. ELF header 可以让操作系统到正确的位置寻找 program headers 与 section headers.
section headers 包含了每个 section 的名字与起始位置, 使用 readelf -S 来查看.
program headers 告诉操作系统为了执行此 ELF 需要到哪些地址(文件偏移量)加载数据到内存, 这些地址也在 section 区域中, 通常是多个 sections 的集合. 使用 readelf -l 来查看.
sections 组成了 ELF 的本体, 而 program headers 与 section headers 是如何使用这些 sections 的元信息. 一般情况下共享库(shared object, 即 .so 文件)是不包含 program headers 区域的, 但是如果有合法的 program headers 并且确实有正确的 main 函数, 共享库也是可以当做可执行程序运行的. 所以共享库和可执行程序并没有本体上的区别.
在那么多的 sections 中, 我们只关心其中的 .rodata 节. rodata 就是 read only data, 它存储着这个 ELF 中的全局共享的数据. 使用命令来读取这一节
$ readelf -x .rodata c_sample
Hex dump of section '.rodata':
0x00000690 01000200 48656c6c 6f00 ....Hello.
0x00000690 是之前在 readelf -S 命令中可以看到的 .rodata 节的起始位置, 01000200 是与操作系统有关的魔数(用来表示内存分配的一些 flag), 在 linux x86_64 平台固定为这个值, 之后就是用户代码里写的字符串字面量(因为是字符串, 最后还有个 \0).
如果使用多个字符串字面量
int main() {
char *string1 = "Hello";
char *string2 = "World";
return 0;
}
那么就可以在 .rodata 里找到多个字符串
Hex dump of section '.rodata':
0x000006a0 01000200 48656c6c 6f00576f 726c6400 ....Hello.World.
现在我们知道程序是怎么运行的了, 下面来练一练
#include <stdio.h>
int main() {
char *string1 = "Hello";
char *string2 = "World";
printf("%s", string1 + 6);
return 0;
}
这段代码在 linux 平台会打印出 "World"
回到最初的问题, 由于字符串字面量一定会被编译到 .rodata 节, 而此节从 ELF 加载到内存后是被操作系统保护的, 是只读的. 之前提到过, 现代操作系统会在程序企图对一个地址进行操作前检查权限, 如果权限不正确也会产生段错误(被中断).
但是以下代码是正确的
char string[] = "Hello";
string[0] = 'h';
因为这实际上是语法糖, 最终编译为(每个字符都对应到机器码里的一个字节, 不会被编译到 .rodata 去):
char string[] = {'H', 'e', 'l', 'l', 'o', '\0'};
这到底是不是语法糖很容易验证, 首先编写以下代码
int main() {
char string1[] = "Hello";
char string2[] = {'H', 'e', 'l', 'l', 'o', '\0'};
return 0;
}
然后编译这个程序. 使用编译器的 debug 模式编译可以使 ELF 包含符号表从而更好地阅读汇编, 例如 gcc -g main.c
接着使用 objdump -S -d a.out 来查看此 ELF 的 .text 节(text 节用于存储指令), 找到其中的 main 函数
0000000000001169 <main>:
#include <stdio.h>
int main() {
1169: f3 0f 1e fa endbr64
116d: 55 push %rbp
116e: 48 89 e5 mov %rsp,%rbp
1171: 48 83 ec 20 sub $0x20,%rsp
1175: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
117c: 00 00
117e: 48 89 45 f8 mov %rax,-0x8(%rbp)
1182: 31 c0 xor %eax,%eax
char string1[] = "Hello";
1184: c7 45 ec 48 65 6c 6c movl $0x6c6c6548,-0x14(%rbp)
118b: 66 c7 45 f0 6f 00 movw $0x6f,-0x10(%rbp)
char string2[] = {'H', 'e', 'l', 'l', 'o', '\0'};
1191: c7 45 f2 48 65 6c 6c movl $0x6c6c6548,-0xe(%rbp)
1198: 66 c7 45 f6 6f 00 movw $0x6f,-0xa(%rbp)
printf("%s %s",string1,string2);
119e: 48 8d 55 f2 lea -0xe(%rbp),%rdx
11a2: 48 8d 45 ec lea -0x14(%rbp),%rax
11a6: 48 89 c6 mov %rax,%rsi
11a9: 48 8d 3d 54 0e 00 00 lea 0xe54(%rip),%rdi # 2004 <_IO_stdin_used+0x4>
11b0: b8 00 00 00 00 mov $0x0,%eax
11b5: e8 b6 fe ff ff callq 1070 <printf@plt>
return 0;
11ba: b8 00 00 00 00 mov $0x0,%eax
}
11bf: 48 8b 4d f8 mov -0x8(%rbp),%rcx
11c3: 64 48 33 0c 25 28 00 xor %fs:0x28,%rcx
11ca: 00 00
11cc: 74 05 je 11d3 <main+0x6a>
11ce: e8 8d fe ff ff callq 1060 <__stack_chk_fail@plt>
11d3: c9 leaveq
11d4: c3 retq
11d5: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
11dc: 00 00 00
11df: 90 nop
非常显然 string1 与 string2 编译后是一模一样的.
所以为了提升代码质量, 对于字符串字面量的正确做法是使用 const, 以免不知道在哪个代码分支里修改了它
char const *string = "Hello";
除零
除零错误在很多语言都有, 除零错误其实是指 除以零(division by zero).
除以零之所以是未定义行为是因为在数学上除以零的结果就是没有定义的. 其实数学上还有好几个没有定义的值, 一些语言会用 NaN(not a number) 来表示这种值. 在 c 语言中这样的表达式是不允许编译的
#include <stdio.h>
int main() {
int result = 1 / 0;
printf("%d", result);
return 0;
}
main.c:4:20: warning: division by zero [-Wdiv-by-zero]
int result = 1 / 0;
^
虽然可以通过以变量相除的方式避开编译器检查
#include <stdio.h>
int main() {
int a = 1, b = 0;
int result = a / b;
printf("%d", result);
return 0;
}
但是并没有什么用, 这样的程序一运行就会产生
Signal: SIGFPE (Arithmetic exception)
FPE 即 floating-point exception, 表示程序执行了一个错误的算术操作. 与 SIGSEGV 类似, 不能通过捕获信号来强行使程序运行下去(handler 会被反复运行).
所以不要再问某个数字除以零等于什么了, 这是不能运行的.
有返回值的函数没有 return
先看以下例子
#include <stdio.h>
int func() {
}
int main() {
printf("Hello\n");
printf("%d\n", func());
return 0;
}
类似 func 这样声明了有返回值却没有 return 的函数, 并非在所有编译器都能编译. 而且会有类似如下的警告
$ clang main.c
main.c:5:1: warning: control reaches end of non-void function [-Wreturn-type]
}
^
1 warning generated.
而即使能编译, 最终的运行结果也取决于编译器和 cpu 架构.
linux x86_64 平台 gcc 7.5.0(c89, c90, c99, c11) 的结果是第二行输出 0
linux x86_64 平台 g++ 7.5.0(c++98, c++11, c++14) 第二行输出 6
linux x86_64 平台 clang 6.0.0(c89, c90, c99, c11) 第二行输出随机数字
如果对此感兴趣可以找一些在线的 playground 把所有编译器都试一遍.
实际上讨论到底会有什么输出是没有意义的, 因为未定义行为的结果会因为编译器, 操作系统, cpu 架构不同而不同. 下面略微讲解一下为什么 g++ 输出 6
首先, 函数退栈的时候需要把返回值交给其调用者, 而函数自身已经退栈, 所以为了传递返回值必须将其存入某个事先约定的寄存器(与 cpu 架构有关), 函数退栈后调用者再到约定的寄存器去获取返回值. 将返回值保存到目标寄存器的操作就是 return.
所以非常显而易见的是, 如果编译器没有做额外的处理(故意刷新 return register), 那么取返回值时, 总能取到上一个调用 return 的函数存入的值.
非常凑巧的是, printf 函数是有返回值的
extern int printf (const char *__restrict __format, ...);
printf 的返回值是成功输出的字符数量. 因此 return register 会被 printf 置为 6, 而 func 没有调用 return. 取返回值时就会取到实际上是上一个退栈的函数的前一个退栈的函数的返回值.
在 x86 架构 cpu 中, 保存小于 32 位的整型返回值的 return register 是 EAX , 这可以用 objdump 来得知, 此处不再赘述. 在 c 语言中能够通过 register 关键字操作寄存器.
#include <stdio.h>
register int eax asm("eax");
int func() {
}
int main() {
printf("Hello\n");
printf("%d\n", eax);
return 0;
}
(第二行输出 6)
x86 平台的 64 位整型返回值会使用 RAX , 而浮点数更是有 XXM0 到 XXM7 (Streaming SIMD Extensions)那么多寄存器联合使用. 所以如果上上个退栈的函数的返回类型和上一个退栈的函数类型不同, 此时甚至会取到"未初始化"的寄存器值.
存在副作用的子表达式
副作用(side effect)的意思是函数会对其调用者的上下文中的某些东西产生改变, 比如函数内部改变了全局变量, 或者函数传入值的表达式本身会改变其调用者所在的上下文中的变量.
很多谭浩强爱好者会问出下面这种问题
#include <stdio.h>
int main() {
int i = 1;
printf("%d %d\n", i++, i);
return 0;
}
(输出 "1 2")(以 linux 平台的 gcc 编译器为例, 下同)
然后开始盲目分析: "i++" 是用完了再加, 所以输出 1, 而到了第二个参数时 i 已经被加过了, 所以输出 2. 谭浩强直呼闭门大弟子.
那我们来试试给第二个 i 再加 1
printf("%d %d\n", i++, i + 1);
此时同样输出 1 和 2
printf("%d %d\n", i++, i++);
这样甚至输出 2 和 1
printf("%d %d\n", i++, ++i);
这更是输出了不可理喻的 2 和 3
幸运的是 jetbrains 用户并不会写出这种代码
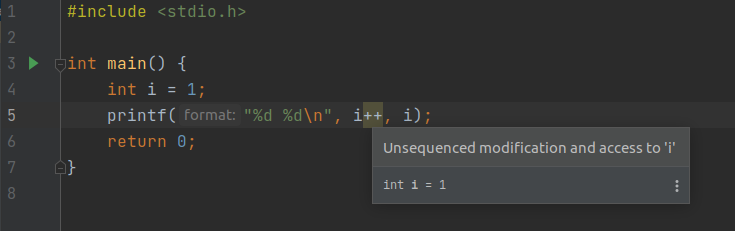
只要能连上互联网, 就可以在 c standard 中找到这个问题的描述
C11: 6.5 Expressions:
If a side effect on a scalar object is unsequenced relative to either a different side effect on the same scalar object or a value computation using the value of the same scalar object, the behavior is undefined. If there are multiple allowable orderings of the subexpressions of an expression, the behavior is undefined if such an unsequenced side effect occurs in any of the orderings.84).
简单地说, 如果一个很长的表达式有多个子表达式, 并且子表达式存在副作用, 那么其运行顺序就是未定义的. 到底是哪个先运行取决于编译器. 所以不要分析了, 这是没有道理的.
另一种常见的场景是在数组问题上
int array[5] = {0};
int i = 1;
array[i] = i++;
(在 linux x86_64 gcc 结果为 array[2] 被赋值为 1)
避免此类问题的方法非常简单, 那就是不要忽略编译器警告
main.c:6:17: warning: unsequenced modification and access to 'i' [-Wunsequenced]
array[i] = i++;
~ ^
1 warning generated.
还有这种大学老师很喜欢考的"重要知识点"
printf("%d", x++ + ++x);
这时的警告会变为 multiple unsequenced modifications to 'x'
也可以写出编译器提示不出来的代码
#include <stdio.h>
int i = 1;
int func1() {
return i++;
}
int func2() {
return --i;
}
int main() {
printf("%d", func1() + func2());
return 0;
}
(linux x86_64 gcc 输出 2)
这种错误就很难追踪了, 在实际项目中应该尽可能避免副作用.
移位操作符的右操作数为负
先看以下代码
#include <stdio.h>
int main() {
int x = 5 << -1;
printf("%d", x);
return 0;
}
某些谭浩强选手会说这里的右操作数会让 int 溢出从而变为 4294967295(2^32 - 1), 实际上并不是, 这是一个未定义行为.
linux x86_64 gcc/g++ 输出 2
linux x86_64 clang 输出 4195536